

Jul 05, 2020
Situation
Development of an interface between a high scale backend to mobile consumer application providing an OTT video streaming service used for on-demand entertainment and mainly high consumption live sports events for a large audience.
Chosen optimization strategy
Implementing Amazon CloudFront distribution deployments in front our 3rd party backend APIs helped to optimize the overall frontend system behaviour and is a very cost effective approach to protect 3rd party backend REST APIs and increase the uptime and availability of our frontend services toward the clients.
Requirements overview
The solution has to fulfil the following high level requirements:
- Serve data and events to clients/users via a GraphQL interface
- Support high concurrent access for a large number of users (100k)
- Support a request rate of up to 2000 requests per second
- Fetch “raw” data from 3rd party REST endpoints
- Protect the 3rd party REST endpoints from too many concurrent requests
- Augment “raw” data with additional information stored in the backend
- Low operational effort and cost
- Elastic solution, since sports event are happening for only a few hours per day/week
Chosen architecture
Based on the above requirements Merapar suggested the following approach:
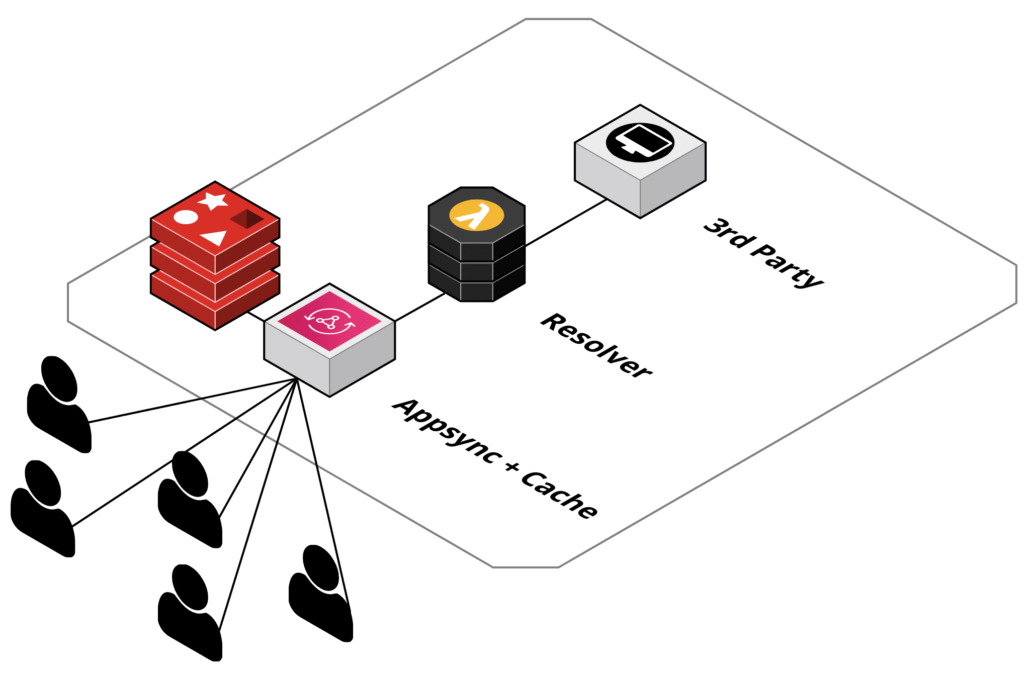
- Use AWS AppSync as a managed service
- Use AWS AppSync integrated API cache
- Use server-less AWS Lambda functions
- AWS Lambda function used as AWS AppSync resolver as integration with the 3rd party REST interfaces
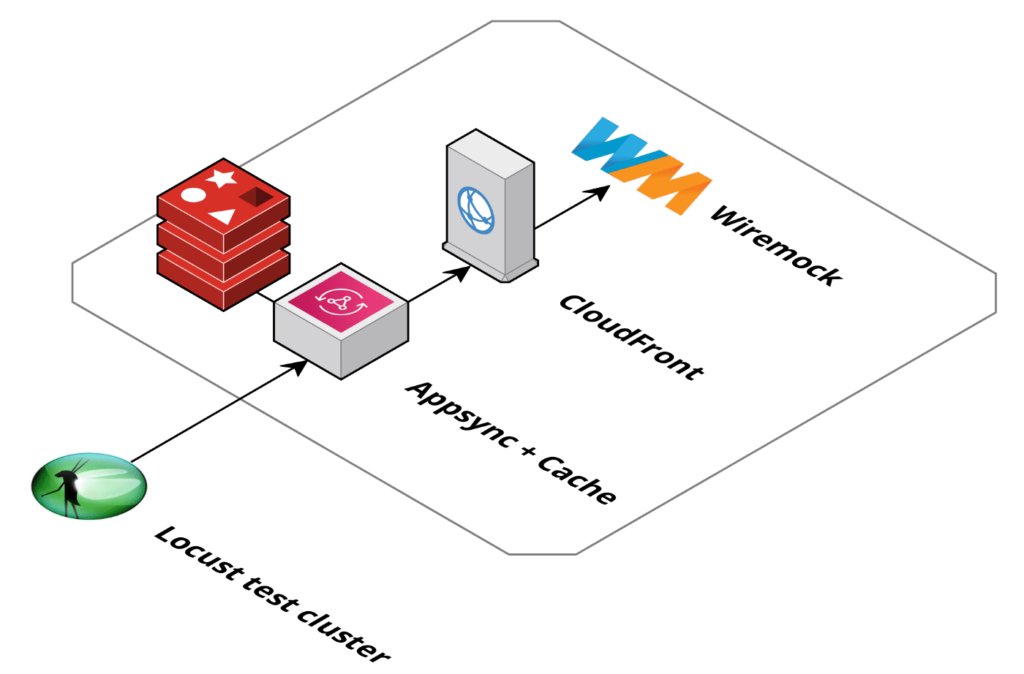
The solution for one REST endpoint can be depicted like following drawing:
Experienced behaviour
System configuration
The following configuration was applied to the AWS setup:
AWS AppSync:
Primary Auth mode: AWS IAM (Not relevant, could be Cognito as well)
AWS AppSync API Cache:
Instance Type: cache.r4.4xlarge
Caching behavior: Per-resolver caching
Cache time to live (TTL): 900 s
AWS Lambda:
Memory: 1024 MB
Unreserved account concurrency: 2500
Load test results
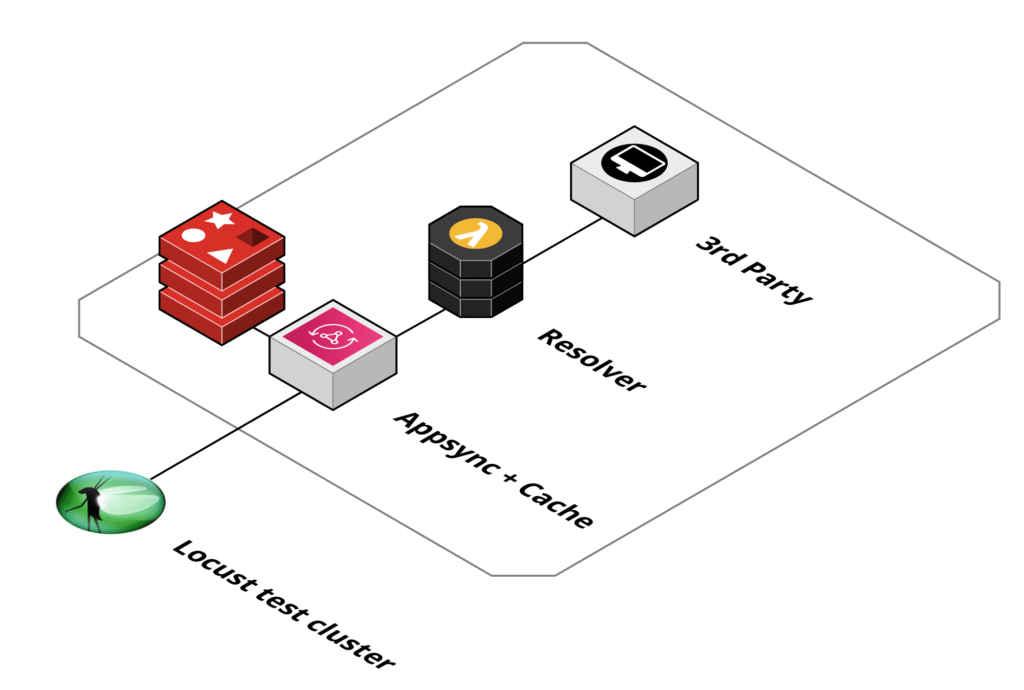
To validate that the chosen solution is fulfilling the requirements, mainly in terms of expected load and concurrency, load tests were executed.
Following setup was chosen for the load tests:
Analysis and background
AppSync Caching
First a bit of background on the caching capabilities of AWS AppSync. This is how AWS describes it: “AWS AppSync’s server-side data caching capabilities reduce the need to directly access data sources by making data available in a high speed in-memory cache, improving performance and decreasing latency.”.
The AppSync service offered caching is done using Amazon ElastiCache Redis instances within the same region as the API. Based on expected load and cache characteristics six instance types are available.

It is possible to choose between two caching strategies ‘Full Request’ and ‘Per-Resolver’ caching. The first will enable caching for all resolvers and cache based on the content of the $context.arguments and $context.identity, the second gives you more freedom and lets you specify the resolvers to cache and the keys to look at.
Important to think about is that the $context.identity map is user specific making the cache also user specific when using ‘Full Request’ caching or ‘Per-Resolver’ caching without custom keys.
Issue Analysis
In order to better analyse the issue seen in the pre-production load tests we set up a test environment where we could control all parts. The Lambda function was replaced with an AppSync HTTP resolver to simplify the setup.
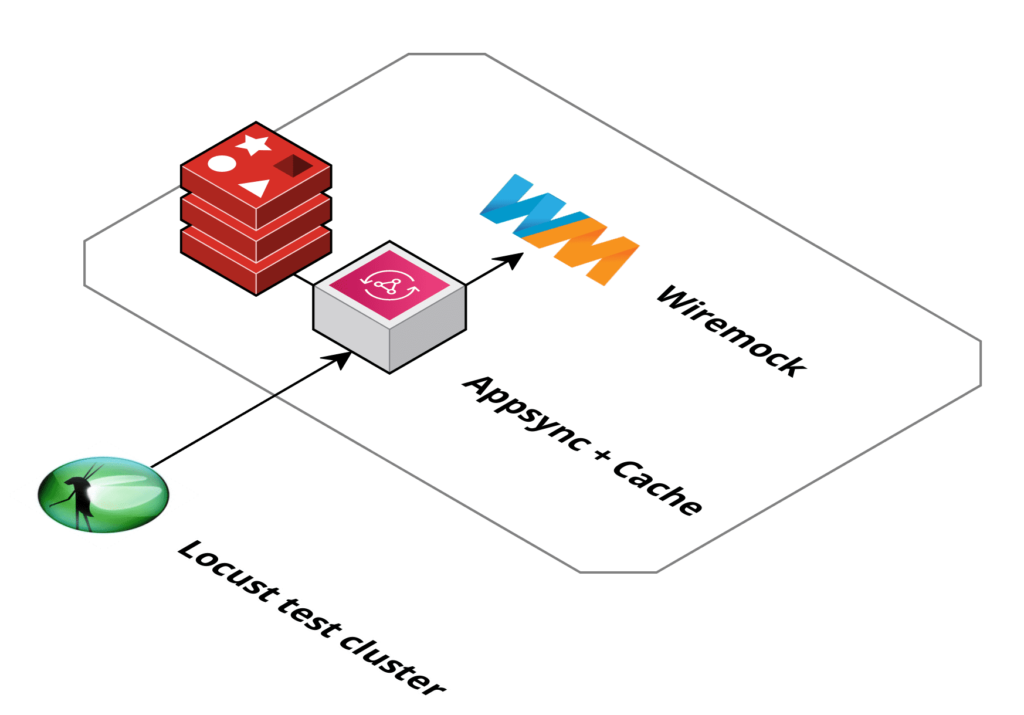
Using WireMock we created an API where we could set the response but also monitor incoming requests and add a static delay.
The MockAPI was added as a HTTP data source and the resolver of a query was set up to use this data source. The TTL was set to 60 seconds.
To see what would happen when the cache expires a static delay of 5 seconds was added to the MockAPI. A ‘load test’ with just 5 users returns the following results.
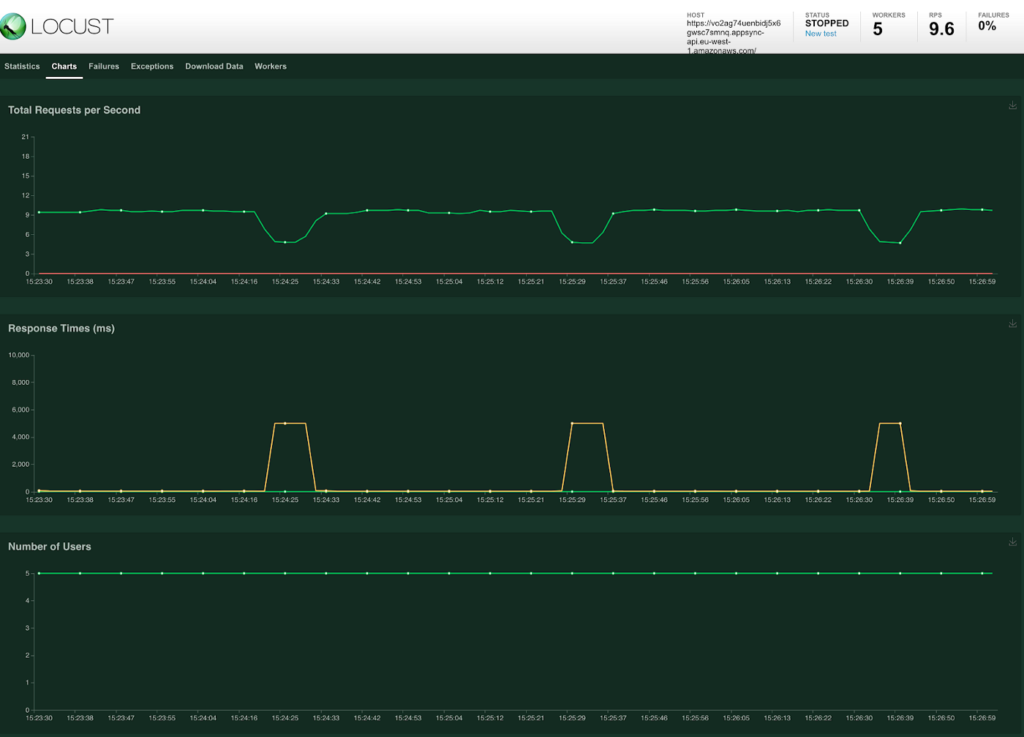
As expected there is a 60 second interval where there is a cache miss and the resolver is called. As this takes 5 second to return the result is a major spike in the response time.
When looking at the requests on the MockAPI it is clear that all requests from the 5 users were actually directly forwarded. After the first request returns the cache is available again and the response time improves.
To get a more realistic load test we lowered the delay of the MockAPI to 500ms and ran the test with 2k users.
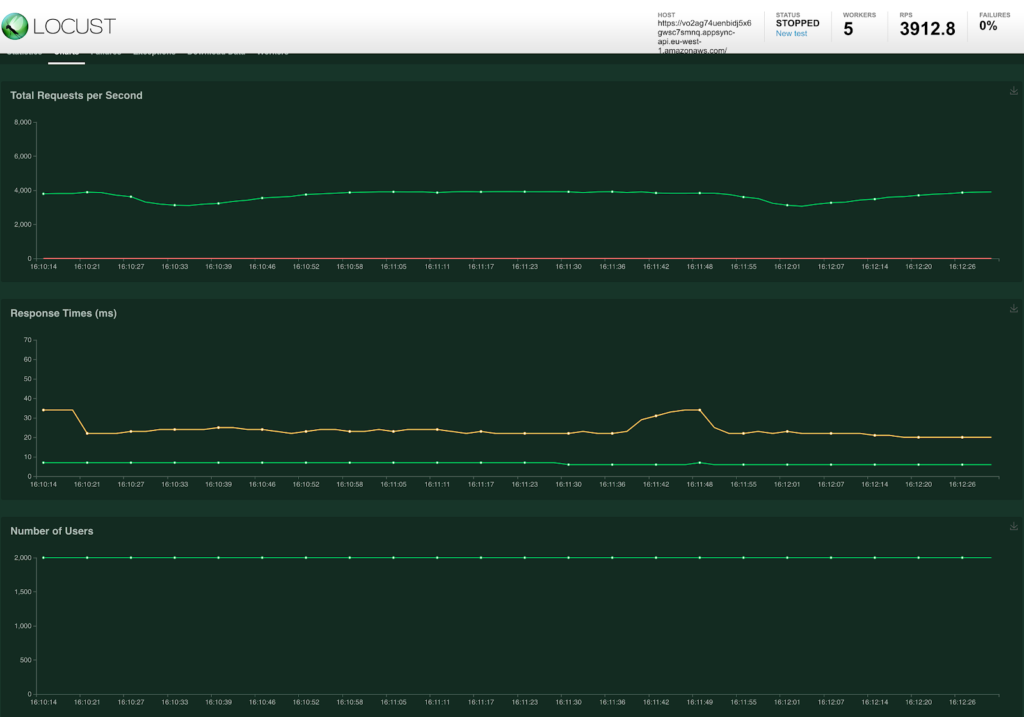
This actually looks pretty good, the averages almost don’t show the fact that the cache expired. But when looking at the MockAPI we see that +- 500 requests were actually received in less than 1 second. Looking at the max response times we can also see that some calls took way longer than the +- 500ms as the MockAPI was struggling to handle the load.
The AWS AppSync dashboard also shows these ‘Cache Misses’ that were forwarded to the MockAPI.
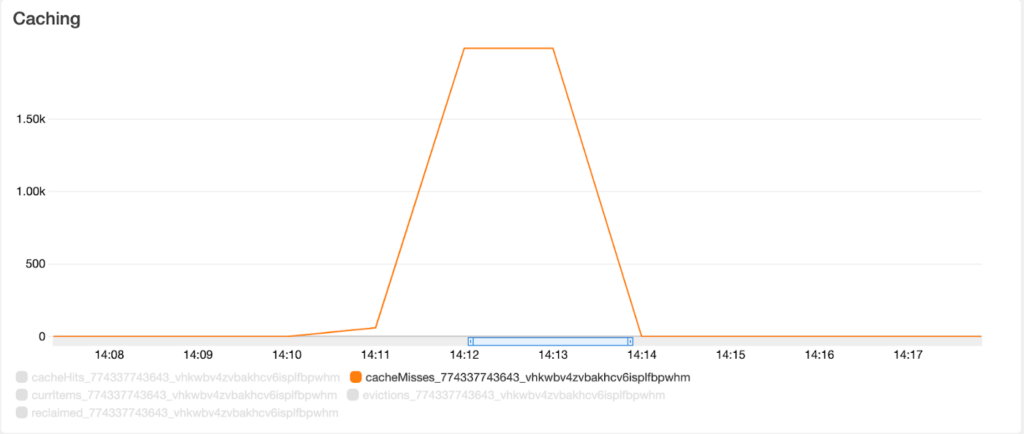
Analysis summary
It appears that the AppSync behaviour when the cache on an entry has expired is to forward all requests directly to the data source. This is fairly common for standard caches and will not be a problem when the concurrent usage of our GraphQL is limited or the service behind the API is a properly scaled application within your own control.
In our case it is a 3rd party REST API that isn’t prepared for this kind of load, and as with most 3rd party API this kind of request pattern isn’t allowed and will most likely be throttled or declined.
Cache Stampede
The issue we are seeing is actually fairly well known when using a cache and is referred to as ‘Cache Stampede’, ‘Thundering Herd’ or sometimes ‘dog-piling’. We will not go into details as there are other good posts about that. The important thing to know is that there are 3 possible mitigation against this issue as also listed on the Wikipedia article here.
Locking
To prevent multiple simultaneous re-computations of the same value, upon a cache miss a process will attempt to acquire the lock for that cache key and recompute it only if it acquires it.
External re-computation
This solution moves the re-computation of the cache value from the processes needing it to an external process.
Probabilistic early expiration
With this approach, each process may recompute the cache value before its expiration by making an independent probabilistic decision, where the probability of performing the early re-computation increases as we get closer to the expiration of the value. Since the probabilistic decision is made independently by each process, the effect of the stampede is mitigated as fewer processes will expire at the same time.
Mitigations
AWS AppSync doesn’t contain any internal mitigations against ‘Cache Stampede’, this means that we need to find the solution externally.
One of the requirements for our solution is that it should be fully managed as that is one of the key reasons to use AWS AppSync instead of hosting an Apollo server.
Backend caching with Amazon CloudFront
Our solution to this problem is deploying an Amazon CloudFront distribution in front of our 3rd party API. Amazon CloudFront is a fully managed solution and very capable of handling the traffic bursts that we have seen during our tests.
Pricing of Amazon CloudFront is based on the volume of data that is transferred and it doesn’t have a fixed price per hour. This also means that if there is limited traffic on our AWS AppSync endpoint there will be very little costs on Amazon CloudFront.
Amazon CloudFront has implemented a solution for ‘Cache stampede’ that falls under the ‘Locking’ category as described in the ‘Cache Stampede’ section.
It is described here as a ‘Traffic Spike’ and the solution is:
If there’s a traffic spike — if additional requests for the same object arrive at the edge location before your origin responds to the first request — CloudFront pauses briefly before forwarding additional requests for the object to your origin
Validation load test
We have updated our test setup by adding a Amazon CloudFront distribution in front of the MockAPI
To MockAPI has been configured as the origin and TTL on the behaviour has been set to 65 seconds to not completely align with the TTL on AppSync.
When we run the load test with the same settings as before (500ms delay and 2k users) we get the following result.
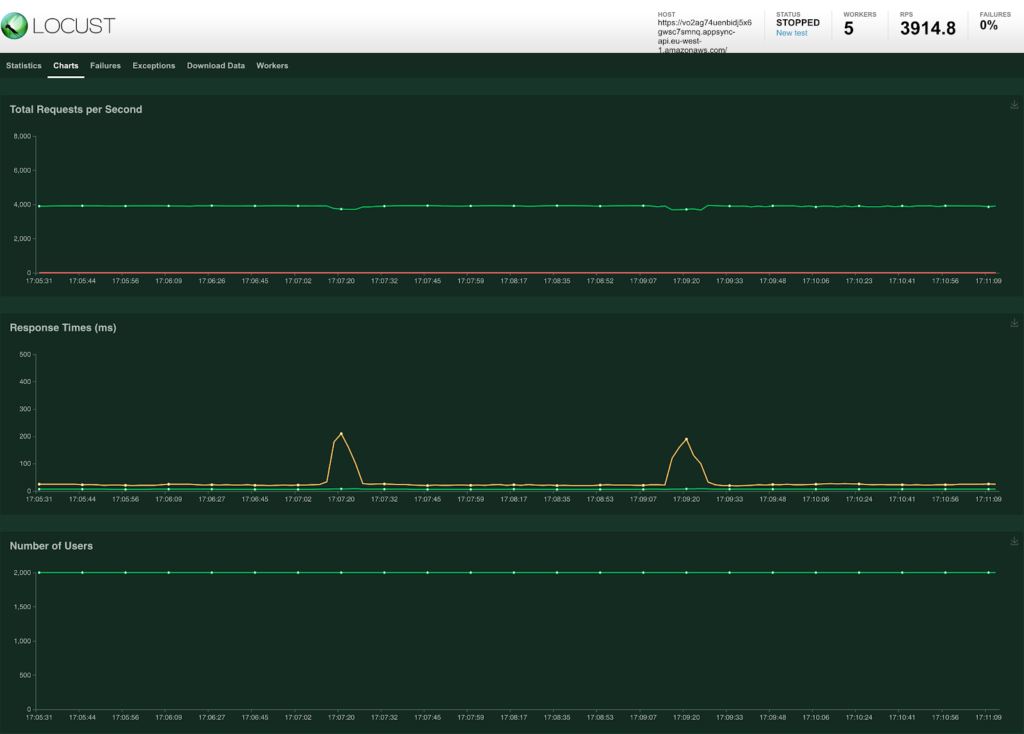
Because we set the TTL on Amazon CloudFront not to align with AWS AppSync we actually only see a real cache invalidation once every 120 second.
The 95th percentile line (yellow line) shows a small increase if you compare it against the previous test while it is still within an acceptable range. It does seem like the request per second line is more stable.
The most important metric to look at is the amount of requests that were forwarded to the MockAPI as that became the issue in the previous test.
The metrics of the MockAPI show that there is only a single request done by Amazon CloudFront every 120 seconds. That means that the brief pause mechanism mitigates the ‘Cache Stampede’ completely.
The AWS AppSync metrics still show the same amount of ‘Cache Misses’ but these are now handled by Amazon CloudFront.
Further optimisations
Using Amazon CloudFront in combination with the AWS AppSync cache would also make it possible to implement an ‘external re-computation’ solution by having another process regularly call the Amazon CloudFront endpoint and keeping the cache warm and with it making sure AWS AppSync always gets a cached response.
The additional benefit would be minimal but might be worth it depending on the situation.