

Sep 07, 2020
Working with Machine Learning, and therefore very often with large and growing data sets, requires from time to time to update and enhance your historic data set. Here we transformed more than 1 billion data records (1,5 TB uncompressed data set), the resulting processing time was 40 minutes (despite 80h in a sequential approach) and the total cost was $ 8.28 for the complete exercise.
Such a schema migration is wanted because new insights are normally gained when working with the data and new additional features can be extracted from the raw data set. This leads to the wish to go back to the historic data and extract the new features to use the full information and richness of the data.
Since the volume is quite large and also diverse, a controlled and managed approach with S3 bucket versioning, S3 object metadata (tags) and AWS Step Functions driven Lambda will be used for that.
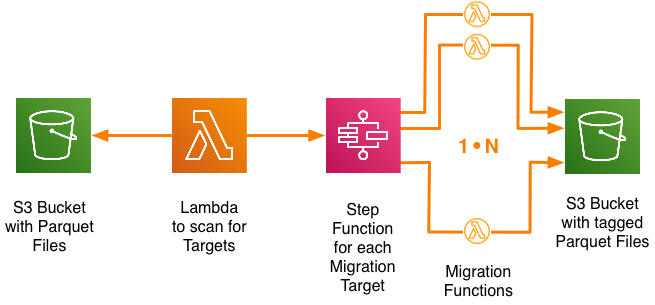
Goal
The goal is to start from a Snappy compressed parquet data set in S3 and migrate selected files to a new version with additional feature columns in the same S3 bucket, since the files will be accessed via AWS Athena. More details about the data set and format can be found in my blog post “Effective data exploration via columnar data formats like Parquet”.
In summary we want:
- Update a large number of objects where the exact state is not known
- In parallel as fast as possible
- In an controlled fashion by applying steps in a certain order
- But we also want to throttle the parallel execution to avoid hitting any limits
Case: Enhance a large IoT sensor data set with new calculated fields
In our case we had 120 data files per day from IoT sensors in the data set and wanted to migrate 60 days of data, so in total 7200 files needed to be migrated. The goal was to add 4 new additional columns, which would be calculated based on new findings and some data processing based on two existing input columns. This could have been done partly during our Athena/Presto queries on the fly, but for several reasons we decided to add these 4 new columns into the files. Parquet doesn’t allow to just add these to the existing data, a new Parquet files has to be written, so we needed to write a Pandas based migration and the reading and writing of Snappy compressed parquet files back to S3 to have them available for the Athena based data analytics. A conversion step was around 40 seconds per file and executing such a conversion sequentially would have taken 80 hours. The process can be extremely parallelized since each conversion is independent. Since such a migration will be applied again at certain times, we opted for a serverless solution which brings the possibility of highly parallel processing and also is only generating cost when be actively used.
The solution: Generation of many state machines to parallel execute the data migration
Following steps will be applied to reach our migration goal:
- A Lambda function scans for target files in the S3 analytics bucket
- For each target file a step function will be created to manage the migration process
- The step functions execute the migration in a parallel manner
- Retry mechanisms need to be in place to deal with execution limits and timeouts
- The migrated objects are written back to the S3 analytics bucket
We will need 3 artifacts to execute the complete migration flow and these are described further below:
- A Lambda function triggered by an event to scan a S3 bucket
- A Step function to manage the migration states for each found target object
- A Lambda function for migration of each target object to the desired version
Step1: Scan for target files
With an initial event the “S3 scanning lambda” can be started. For this we use an input event which can either be started via a Cloudwatch event or manually in the Lambda console and it looks like following:
{
"bucket": "myAnalyticsBucket",
"prefixes": [
"parquet/year=2019/month=3/"
],
"type": ".parq.snappy",
"filter": "sensorData_",
"schema": "schema:sensorData:version",
"desiredVersion": "3"
}
Here it is targeting a single bucket, looking for a specific prefix pointing to the partitioned storage set for month March, files with the ending .parq.snappy and contain in the name sensorData_ and should be ending up with a version tag of 3. Here also the tag which we will add the the S3 objects is defined and its key is called schema:sensorData:version and the value will be a version number. The tag key should be adapted based on the underlying raw data format.
The simplest event would look like:
{
"bucket": "yourBucketNameGoesHere",
"prefixes": [
""
],
"type": "",
"filter": "",
"schema": "schema:yourSchemaNameGoesHere:version",
"desiredVersion": "2"
}
It will scan your specified bucket, will take all objects it finds and adds a tag called schema:yourSchemaNameGoesHere:version and a value of 2 for this tag. The values you can enter for prefixes, type and filter just allow to reduce the targeted objects in the bucket.
The lambda function for scanning looks as following:
import boto3
from datetime import datetime
import json
import os
# Constants
stepFunctionARN = os.getenv('stepFunctionARN', 'arn:aws:states:eu-west-1:XXXXXXXXXXXX:stateMachine:ParquetSchemaMigrate')
# Functions
def getMatchingS3Objects(bucket, prefix='', suffix='', filter=None):
"""
Get the matching target files
"""
s3 = boto3.client('s3')
while True:
# The S3 API response is a large blob of metadata.
# 'Contents' contains information about the listed objects.
resp = s3.list_objects_v2('Bucket': bucket)
try:
contents = resp['Contents']
except KeyError:
return
for obj in contents:
key = obj['Key']
# filter out none matching
if key.startswith(prefix) and key.endswith(suffix):
if filter != None:
if filter in os.path.basename(key):
resp2 = s3.get_object_tagging(Bucket=bucket,Key=key)
obj['TagSet'] = resp2['TagSet']
yield obj
else:
resp2 = s3.get_object_tagging(Bucket=bucket,Key=key)
obj['TagSet'] = resp2['TagSet']
yield obj
# The S3 API is paginated, returning up to 1000 keys at a time.
# We pass the continuation token into the next response, until we
# reach the final page (when this field is missing).
try:
kwargs['ContinuationToken'] = resp['NextContinuationToken']
except KeyError:
break
def getSchemaVersion(tagSet,schema):
#if no matching tag is present, asume initial version 1 and assign it default here
schemaVersion = 1
for tag in tagSet:
if tag['Key'] == schema:
schemaVersion = tag['Value']
return schemaVersion
def lambda_handler(event, context):
# Read the input event
bucketname = event["bucket"]
prefixes = event["prefixes"]
objecttype = event["type"]
filter = event["filter"]
schema = event["schema"]
desiredVersion = int(event["desiredVersion"])
# Get the candidate keys
candidateFetchkeys = []
for prefix in prefixes:
for obj in getMatchingS3Objects(bucketname, prefix=prefix, suffix=objecttype, filter=filter):
candidateFetchkeys.append({'Key': obj["Key"], 'TagSet': obj["TagSet"]})
# Check if a migration step is needed, based on the schema version tag
fetchkeys = []
for fetchkey in candidateFetchkeys:
schemaVersion = int(getSchemaVersion(fetchkey["TagSet"],schema))
if schemaVersion < desiredVersion:
fetchkey['schemaVersion'] = schemaVersion
fetchkeys.append(fetchkey)
# invoke stepfunctions
client = boto3.client('stepfunctions')
for fetchkey in fetchkeys:
executionName = os.path.basename(fetchkey['Key']) + "_" + str(int(datetime.utcnow().timestamp() * 1000))
input = {}
input['state'] = "Start"
input['s3Bucket'] = bucketname
input['s3Key'] = fetchkey['Key']
input['schema'] = str(schema)
input['desiredVersion'] = str(desiredVersion)
response = client.start_execution(
stateMachineArn=stepFunctionARN,
name=executionName,
input=json.dumps(input)
)
print('Started State Machine {0!r}
successfully'.format(response['executionArn']))
return
Best is to set the targeted step function as an environment variable of the lambda function. The key would be stepFunctionARN and the value the ARN of your step function which looks something like:
arn:aws:states:eu-west-1:XXXXXXXXX:stateMachine:ParquetSchemaMigrate
where XXXXXXXXX represents your AWS account id.
For each matching object a state function is generated, as in our example above, this can be a few thousands.
Step2: Execute the migration for each object as step function
The following step function controls the migration process of the object state:
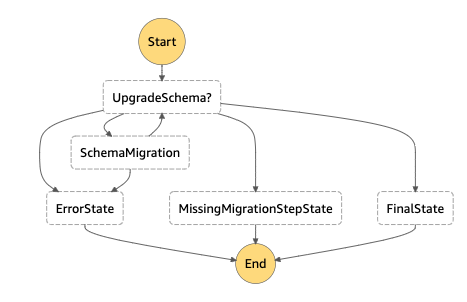
The schema version is checked and when not in the desired version, a lambda function for the schema migration step is triggered.
{
"StartAt": "UpgradeSchema?",
"States": {
"UpgradeSchema?": {
"Type" : "Choice",
"Choices": [
{
"Variable": "$.state",
"StringEquals": "Done",
"Next": "FinalState"
},
{
"Variable": "$.state",
"StringEquals": "Error",
"Next": "ErrorState"
},
{
"Variable": "$.state",
"StringEquals": "MissingMigrationStep",
"Next": "MissingMigrationStepState"
}
],
"Default": "SchemaMigration"
},
"SchemaMigration": {
"Type" : "Task",
"Resource": "arn:aws:lambda:eu-west-1:XXXXXXXXXXX:function:MigrateParquetfunction",
"TimeoutSeconds": 330,
"Retry": [ {
"ErrorEquals": ["Lambda.TooManyRequestsException"],
"IntervalSeconds": 30,
"MaxAttempts": 10,
"BackoffRate": 2.0
} ],
"Next": "UpgradeSchema?",
"Catch": [ {
"ErrorEquals": [ "States.ALL" ],
"Next": "ErrorState",
"ResultPath": "$.error"
} ]
},
"ErrorState": {
"Type": "Fail"
},
"MissingMigrationStepState": {
"Type": "Fail"
},
"FinalState": {
"Type": "Succeed"
}
}
}
The step function is initiated in Step1 with a State=Start, it will return a different state, which is either:
- Migrating (If the desired version is not yet reached)
- Done (If the desired version is reached)
- MissingMigrationStep (If the migration to the desired version is not defined yet)
- Error
Important is to set the values for Retry to the right values, which needs a bit of fine-tuning. Also you have to change the Resource value of the task to the right ARN of your lambda function for the schema migration.
The AWS limits for step functions is to have 10,000 registered state machines (we have here just one) and 1,000,000 open (running) executions, which we bellow limit anyway to 100, which will be determined by the account concurrent lambda execution limit (default: 1000). So it is very hard to get anyway near these limits, if limits have to be considered then mostly the API Action Throttling limits calling the Step Functions API.
Step3: Execute the migration function
The analytics bucket we are using has versioning on and also a lifecycle policy, this allows us to revert to earlier versions of the files is something goes wrong.
The lambda function for the migration gets as input the key to the s3 object and also the key of the object tag to look for, in our case schema:sensorData:version and also the desired version number. Since initially no tag will be present, after the initial migration, the version will be set to 2.
import json
import logging
import pandas as pd
import os
import snappy
import fastparquet as fp
import s3fs
# Constants
DEBUG = True
# Globals
logger = logging.getLogger()
if DEBUG:
logger.setLevel(logging.DEBUG)
else:
logger.setLevel(logging.INFO)
# Internal migration functions
def _migration_1_2(parqName, s3):
logger.info("Started migration version 1->2 for s3://{}".format(parqName))
myopen = s3.open
logger.info("Read object s3://{}".format(parqName))
pf = fp.ParquetFile(parqName, open_with=myopen)
# load into Pandas dataframe
df = pf.to_pandas()
# Do some stuff here with you data frame
# Write the resulting data frame back
logger.info("Write object s3://{}".format(parqName))
fp.write(parqName, df, compression='SNAPPY', open_with=myopen)
# change the acl
s3.chmod(parqName, acl='bucket-owner-full-control')
return
def _migration_2_3(parqName, s3):
logger.info("Started migration version 2->3 for s3://{}".format(parqName))
# Add migration actions here
return
# Defined migrations
migrations = {
'1->2': _migration_1_2,
'2->3': _migration_2_3,
}
def lambda_handler(event, context):
schema = event["schema"]
desiredVersion = event["desiredVersion"]
s3Key = event["s3Key"]
bucket = event["s3Bucket"]
parqName = bucket + "/" + s3Key
s3 = s3fs.S3FileSystem()
#get the existing tagset from the object
tagset = s3.get_tags(parqName)
logger.debug("Existing Tags: {}".format(tagset))
# set the new Version
if schema in tagset:
existingVersion = int(tagset[schema])
else:
# default to a modified version 2 if the tag is absent
existingVersion = 1
newVersion = str(existingVersion + 1)
newTagset = {schema: newVersion}
tagset.update(newTagset)
logger.debug("Updated Tags: {}".format(tagset))
logger.info("Started execution: {}".format(i))
migrationString = str(existingVersion) + "->" + str(newVersion)
logger.debug("Calling migration: {} for s3://{}".format(migrationString, parqName))
try:
migrationResult = migrations[migrationString](parqName, s3)
except KeyError:
logger.warning("Migration step {} not defined. Please update the lambda function".format(migrationString))
event['state'] = "MissingMigrationStep"
event['errorCause'] = "Migration step {} not defined. Please update the lambda function".format(migrationString)
return event
except Exception as details:
logger.error("Unexpected error: {0}".format(details))
raise
#update tags
s3.put_tags(parqName, tagset, mode='m')
if desiredVersion == newVersion:
event['state'] = "Done"
logger.info("Set state to 'Done' with version {} for object s3://{}".format(newVersion, parqName))
else:
event['state'] = "Migrating"
logger.info("Set state to 'Migrating' to version {} and with desired version {} for object s3://{}".format(newVersion, desiredVersion, parqName))
return event
The actual migration functions are called by its string-type name which avoids to write many if-statements and deep levels of indentations. Details can be found in the blog post called “Python: Call Functions by String”.
We use here mostly S3 as resources and here a massively parallel access is possible. To throttle the concurrency and also to exhaust an underlying resource, the “Concurrency” setting of the Lambda function is set to “Reserve concurrency = 100”. This allows a parallel execution of 100 and otherwise an exception called “TooManyRequestsException” will occur. The step function have to handle these exceptions and via the Retry settings initiate a retry after some time and with a certain backoff. For this the definition of the step function has to be tuned accordingly.
Results
The implementation of the data migration in the here mentioned approach allows for a massively parallel execution and therefore a very short duration of this process. The migration of the 7200 files, which would sequentially take 80 hours, was executed in around 40 minutes. This time was a result of the timeout values and also incrementally increased backoff of the longer pending step functions. As mentioned the parallel execution was limited to 100 at a time to protect underlying resources. Also the usage of step functions give a clear overview of the status of each file, e.g. during initial runs 2 files had a resulting error state. Investigating these 2 files showed that they contained unexpected data and the migration scripts needed to be extended to handle such cases. After these changes were applied, the same scanning function could be triggered and the remaining files were identified and then migrated into the correct version and state.
Also the cost for this migration was very low, since it was mainly the pure Lambda execution time during the migration. In total a charge of $ 8.28 occurred, with $ 1.42 for the step functions and $ 6.86 for the lambda service, and this included some test runs. Until the next migration need, the cost is $ 0 and then the process can be started again with a high concurrency.
Final remark
AWS announced recently the feature “Amazon S3 Batch Operations”. This new feature allows to process all objects in a S3 bucket and then apply certain processing steps and also to invoke an AWS Lambda function. In our case this would replace the initial scanning function but the rest would stay the same. In general for this use case, I don’t see much advantage to use a S3 Batch Operations approach.